 Expressions Generation
Expressions Generation
We construct our dataset GITM-MR by a generation program to create mismatch expressions from the corresponding original expressions by partial replacement. First, we identify all the relation phrases in the expressions of the Ref-Reasoning dataset by using an off-the-shelf parser. After that, we manually select a subset of 27 commonly-occurred relations, and assign some relations acceptable to similar contexts but with different semantics, for each relation in the subset, as their replacement candidates. For example, we assign "carry" as an candidate for "wear", and "to the left of" as an candidate for "to the right of". Utilizing human annotations as such significantly reduces the linguistic bias and false negative cases on the generated expressions. Finally, we replace one relation in each expression by a candidate to construct a mismatch expression. The program keeps the relation phrase set and the replaced relation for each expression as the labels for MRR evaluation.
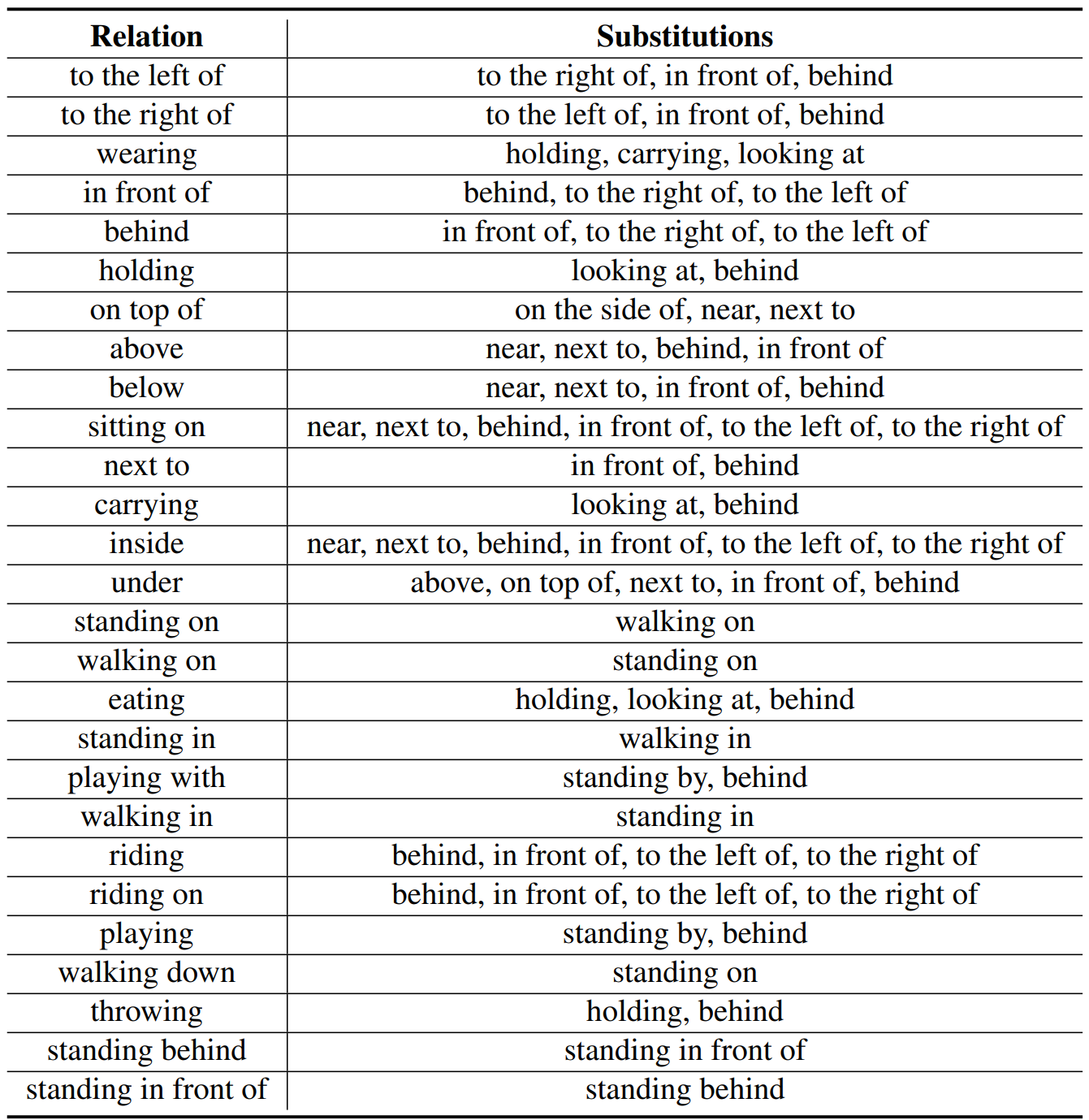
Mismatched relation diversity. In the real-world scenario, the mismatched expressions should be various as the matched expressions, rather than showing certain patterns which are easy to identify. To keep the diversity, we assign multiple substitutions for each relation. The full replacement candidate list is shown in the following table for the reference. We randomly select the substitution when replacing a relation.
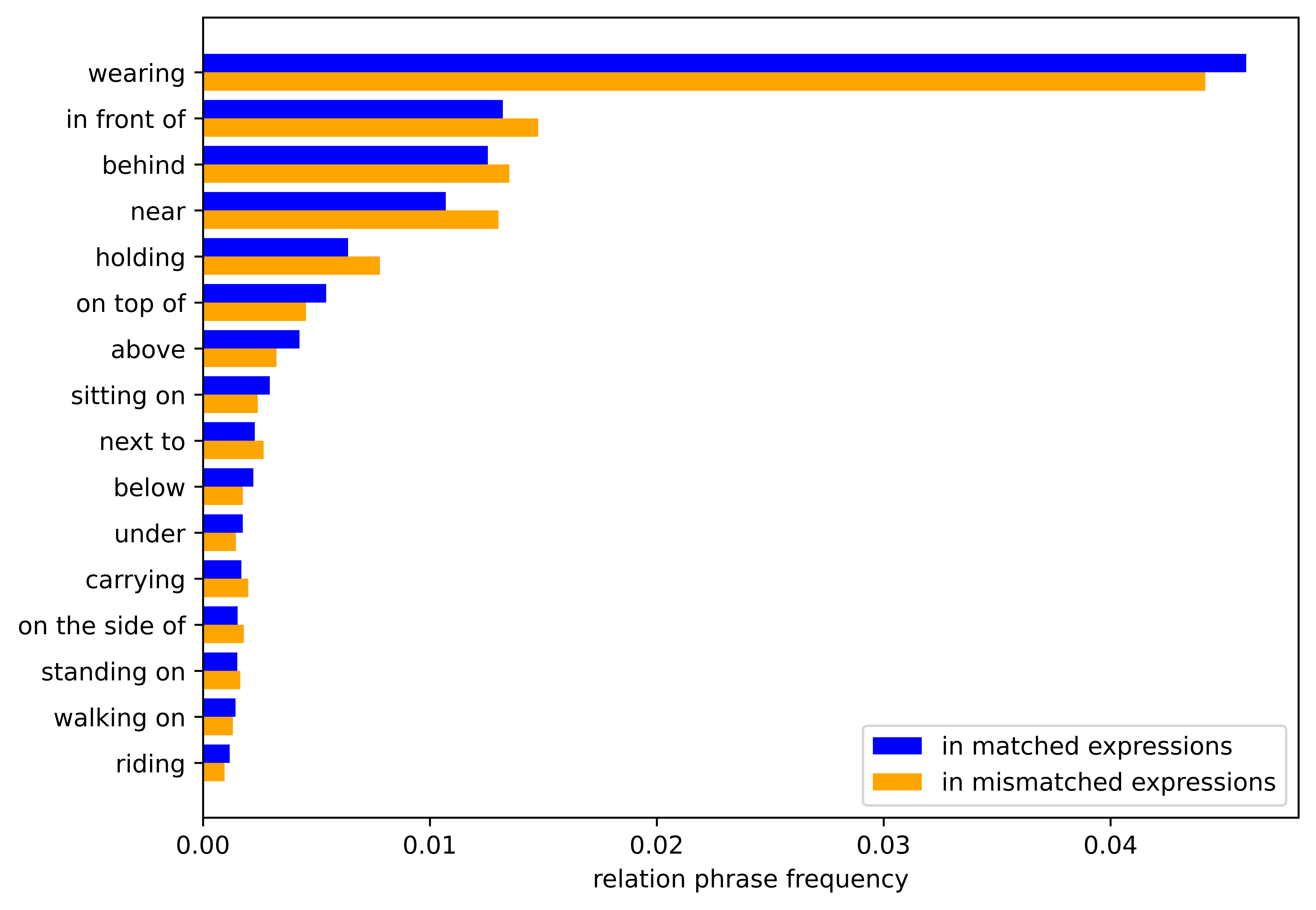
Linguistic bias. The generated mismatched expression should have close perplexity in the pre-trained language model BERT with the original matched expression. After the substitution, the relation phrase occurrence distribution in matched and mismatched expressions should be close. We count the distribution of sentence perplexity in the range of 0 to 105 in the left figure, and the frequencies from the main body of the relation phrases belonging to the substitution list in the right figure. The statistics of matched and mismatched expressions in the validation set are shown by the bars with different colors. The results demonstrate the high similarity between matched and mismatched expressions.
False mismatch. There still exist image-text pairs where a relational phrase in an expression is replaced, but the entire expression still perfectly describes an object in the image. We call these false mismatched cases. To avoid those unwanted cases from hurting the quality of testing, we hired annotators from Stardust to label the mismatch cases in the test set, indicating whether the constructed mismatched sentence description in each case can match an object in the image. In the end, we only keep the cases that the annotators identified as mismatch in the test set. The final test set contains only the reserved mismatch cases and their corresponding matched cases.
 Cases
Cases
The following images show the generated cases in our dataset with the inference process conducted by our model RCRN.

BibTeX
@misc{wu2023grounded,
title={Grounded Image Text Matching with Mismatched Relation Reasoning},
author={Yu Wu and Yana Wei and Haozhe Wang and Yongfei Liu and Sibei Yang and Xuming He},
year={2023},
eprint={2308.01236},
archivePrefix={arXiv},
primaryClass={cs.CV}
}